
题图来自于NextDay
田丁按:
身为程序员,最大的好处就是,有个什么需求,自己实现一下就可以了,自给自足。如果实现不了,主要原因基本是—— 懒,另外就是这个需求目前还有替代方式存在,即便很费事,但还处于自己可以接受的范围,或者说,自己做的代价太高,学习成本、经济成本、时间成本等等。
做产品的时候,经常挖空心思去分析用户会有什么样的需求,紧盯着别人,却很容易忘记把自己代入情境,问一下自己如果是用户,会有什么样的需求。
所以,在很难找到或者评估他人需求的时候,暂且抛开要做个什么爆款的想法,先尝试着解决一下自己的需求吧。
前几年参加活动,买了好几年的 Kindle Unlimited(以下简称 KU ),但出于种种原因(“没时间”这种没底气的借口就不说了),起初一直处于闲置状态,从去年疫情开始,才开始真正利用了起来。
我看书的路径,基本是这样的:
公众号/好友推荐/自己发现 -> 豆瓣看下评分 -> 查找是否有 KU 版本 -> 豆瓣标记想读(标记 Kindle 标签) -> 立刻/择日开始看
以公众号为例,大致的一个操作流程是这样:
这样繁琐和重复的工作当然应该程序来做,那么,我们试着想一下,有这样一个系统,输入一个网址,然后自动搜索网页中的书籍名称,并且获取豆瓣评分,用户勾选感兴趣的书名,自动查询是否有 KU 版本并显示 KU 版本的网页地址,标记豆瓣想读,同时加上标签“Kindle”。
“看上去不难,那么就动手开始做吧”,事实上,每次遇到「看上去不难」的想法,现实总是会浇一盆冷水。
我们先来拆分一下需要做的任务:
☑️ 获取网页内容中的书名
❓通过书名搜索到豆瓣该书的页面
❓通过书名搜索到 KU 的页面
❓标记豆瓣想读并添加标签
第一步根据之前的爬虫基础( 参见 如何用 Python 写一个最简单爬虫),比较容易实现,我们先不说机器学习那套,就通过最简单的关键字——《》,来搜索即可。
第二步,就有点卡壳了,豆瓣 API 已经关闭,要查询到一本书的精确地址,只有两个办法,一个是知道这本书的 ISBN 号,然后拼接出 URL 即可;另一个则是,把豆瓣上所有的书爬下来存成一个库,在库里搜索。当然也有人提供现成的库或者是基于现成的库又封装了一个 API,但是依赖别人的库总是会有所限制,而自己爬库,存在定期更新的问题,需要定期维护。
那么,看起来,我只有一条路走了,就是先想办法通过书名找到 ISBN 号,于是开始看各种接口,甚至还尝试爬了下图书馆的查询页面🤦♀️
Two thousand years later……
事情变得很复杂了,似乎又要回到自己建库的环节,建一个 ISBN <-> 书名的匹配库……
明明是个小需求,结果要变成一个巨大的工程了,想想就脑壳疼,先放一放,先放一放……
这一放,就差点被遗忘了。直到我用 Python 写另一个爬取任务的时候才想起了这件事,然后莫名其妙闪过一道光

暂且先放弃我的全自动流程,先来个半自动,能用起来就行。我又仔细考虑了自己的“痛点”,就是不想复制粘贴手工搜索嘛!先解决这个问题好了!
放下完美主义,放下全自动,不一会儿就把脚本写好了。
找了个 Kindle 榜单做测试(原文在这里:重磅!《亚马逊Kindle年度阅读榜单》权威发布!)
出来的结果类似这样:

「原文」是指在文章中出现这个书名的上下文,有些加了《》的也未必是书籍名称,像第一个「XX阅读榜单」就不是了,当然也可以用关键词去排除,但人看一眼也无大碍,所以把原文放在这里是为了参考一下。
豆瓣链接,我用了最简单的网址拼接,所以点击豆瓣图标出来的不是那本书的页面,而是搜索结果的页面,KU 同理,其他两个超链接也是同理。
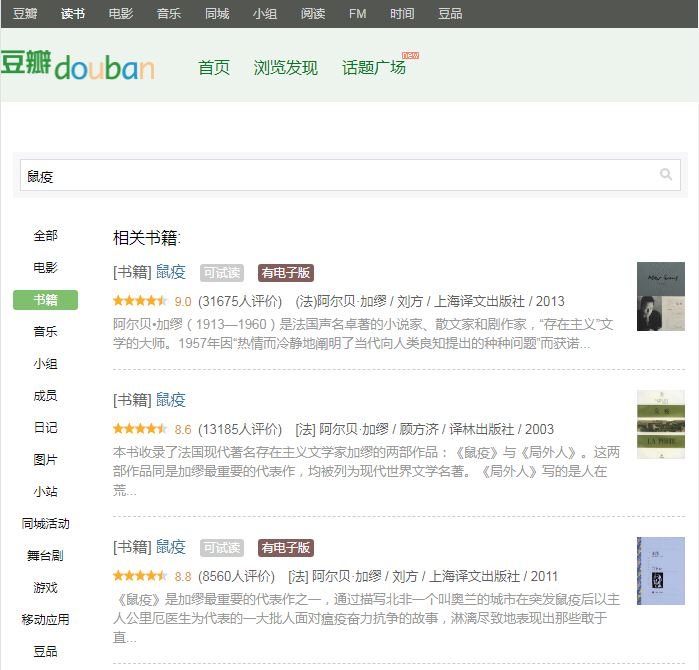
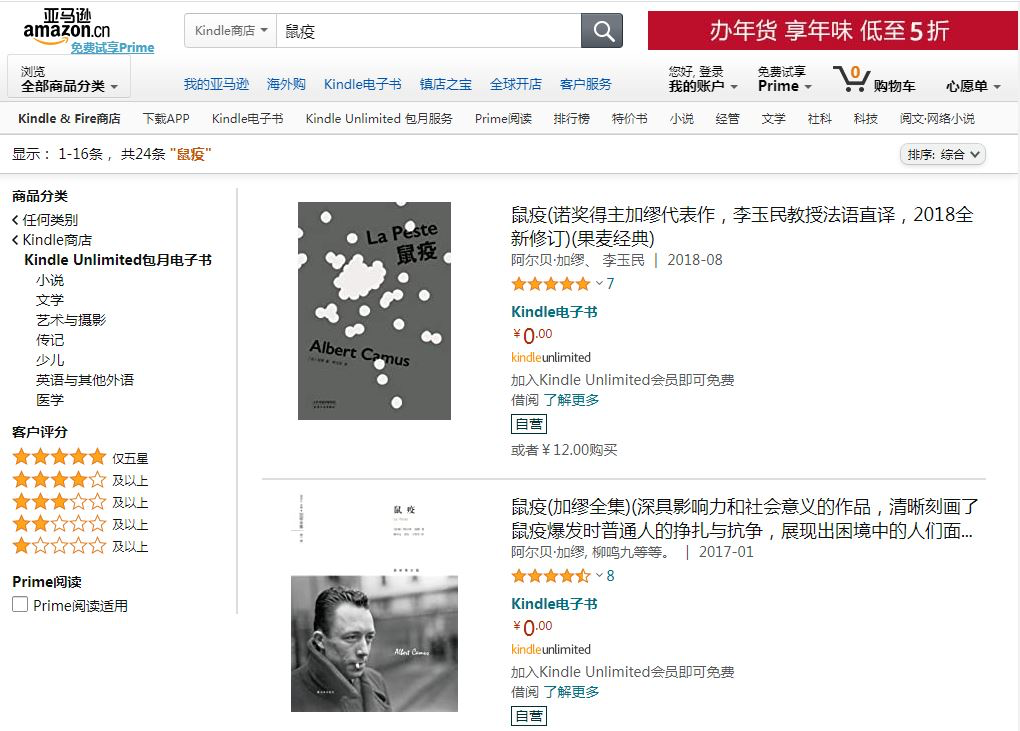
因为 KU 可读书籍是动态更新的,比如上个月还可以免费借阅的,下月就变成了需要购买的版本,所以有这样一个功能,当我想看的时候,只需要点击一下 KU 的链接,就能看到当前是否有可用版本。
不完美也不是全自动,但这样已经节省了我大部分的时间,只需要把有书单的网址复制一下,就能得到这样一个表格(是个网页),剩下的就是用鼠标点点点。
但这种情况,是适合于已经有书单的情况下,那么如果是自己已经标记了豆瓣想读(任意一个没有设置仅自己可见的豆瓣用户都可)的书呢,当然也是同理可实现:
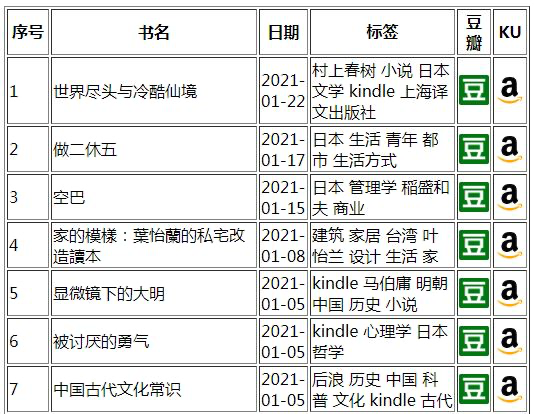
然后就发现,其中有一些当时被我标了「Kindle」标签的,目前已经没有可用 KU 版本了,所以,读书要趁早😅
心满意足地速度实现了自己的两个小需求,虽然不完美,虽然有更高级的方法,但还是挺开心的,顺便可以刷新下 Python 的技能。
不知道有多少人会有跟我类似的需求呢,欢迎留言或者转发点赞,人数多的话1,我就写一篇 HOW TO 来讲讲实际如何写这样一段代码(掰手指就能想出来的高手们请绕行😄)。
哈哈哈,人不多也会写的,台阶给自己留好 ↩︎
发送给作者