
题图来自于NextDay
微信语音这个让很多人既爱又恨(无奈)的功能,我大概是属于后者,因为很多时候不方便直接听语音,当然对方可能恰好相反,很多时候腾不出手打字或者打字比较麻烦。那么,就各退一步,合理范围内尽可能互相理解吧。
基本上只有跟还不能认全字的小朋友或者手上实在没空又急需回复的时候,我才会发语音。鉴于这个原因,对于这个功能本身,至今的印象仅仅停留在「按住说话,松开发送」这个级别,直到今天,后知后觉,才发现了两个有趣的“新增”功能,也不知何时新增的。
功能一:语音转出的文字带表情
起因是跟朋友聊天,发了个语音过来,习惯性地转换成了文字,一转换有趣的事情来了,文字中「无语」后面加了一个气愤的表情,于是我又尝试了「不高兴」,得到的结果是这样的:
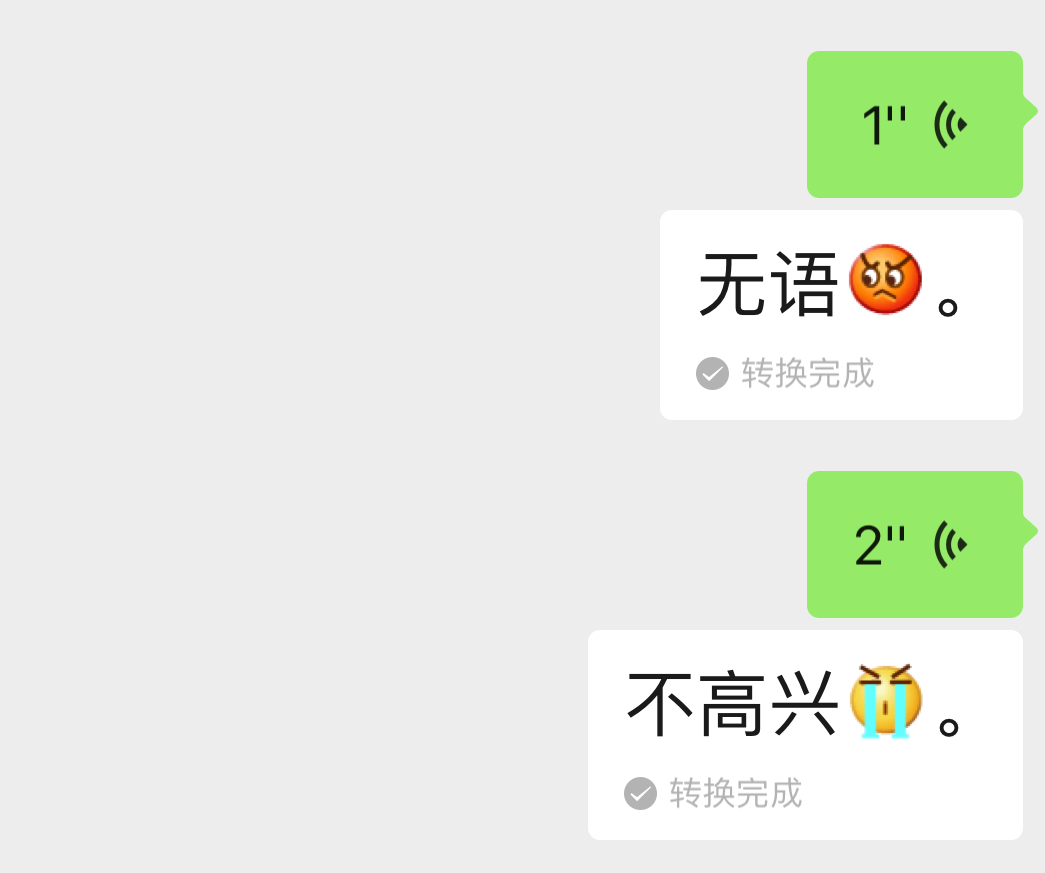
在起初看到「无语」和「无语![]() 」表情的时候,凭借学过的一点数据挖掘的知识,我第一时间想到的是「文本情感分析」。
」表情的时候,凭借学过的一点数据挖掘的知识,我第一时间想到的是「文本情感分析」。
文本情感分析(也称为意见挖掘)是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。
通常来说,情感分析的目的是为了找出说话者/作者在某些话题上或者针对一个文本两极的观点的态度。这个态度或许是他或她的个人判断或是评估,也许是他当时的情感状态(就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)。
摘自 维基百科
情感分析可以用在哪呢?
最常见的是用于评论的情感倾向分析,比如商品评价、酒店入住评价等等,面对海量的用户评论数据时,靠纯人工的方式几乎不可能完成,所以我们需要借助计算机的力量来实现。但目前还做不到完全依赖计算机,计算机真是帮我们把一些预处理和预分类做掉,必要的时候还是需要人工审核。
目前情感分析主要有两种方法:
基于情感词典,是指根据已构建的情感词典,抽取待分析文本的情感词,然后计算其情感倾向。
基于机器学习的情感分析,是指选取情感词作为特征词,将待分析文本向量化,利用分类器(LR、SVM等)进行分类。
基于词典的方法相对比较简单,也容易实现,我们先从这个说起。
情感词典一般主要包括:情感词和程度词。用户用情感词表达自己的态度,比如:喜欢、讨厌等;而用户用程度词表达强弱程度,比如:非常,一般等。
看上去似乎不难,网上也可以找到一些开源的词典,当然也可以自己根据算法去生成一个。我们来看个例子,来自大连理工大学信息检索研究室的中文情感词汇本体1
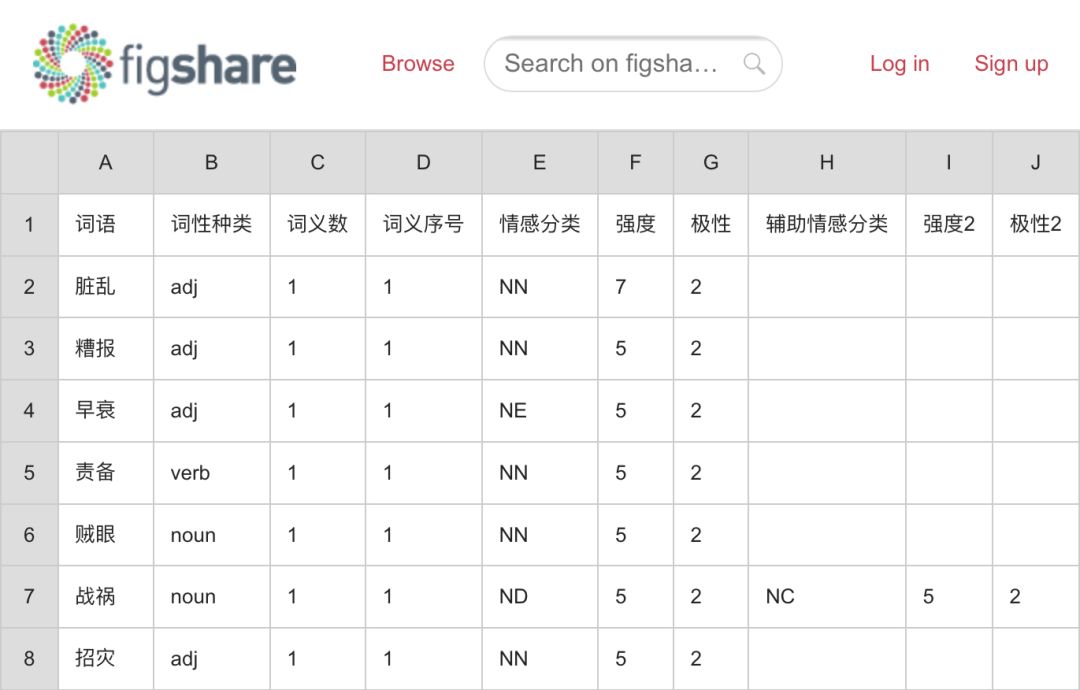
着重看一下「情感分类」「强度」「极性」这三列。
情感分类:按照论文《情感词汇本体的构造》所述,情感分为7大类21小类。
强度:分为1,3,5,7,9五档,9表示强度最大,1为强度最小。
极性:每个词在每一类情感下都对应了一个极性。其中,0代表中性,1代表褒义,2代表贬义,3代表兼有褒贬两性。
注:褒贬标注时,通过词本身和情感共同确定,所以有些情感在一些词中可能极性1,而其他的词中有可能极性为0。
比如「责备」这个词的构造就是:
情感分类:18 贬责(NN) 呆板、虚荣、杂乱无章、心狠手辣
强度:5,位于第三档
极性:2,贬义
完成这一层转换之后,计算机就会知道「责备」是个强度为5的负面词。
一句话是由多个词语组成,如果想要知道一句话的情感倾向,很自然的,我们会想到把句子拆分成若干个词语,通过词典我们可以知道每个词语的属性,那么把这句话里各个词语的属性通过某种算法进行计算,是不是就可以得出这句话的情感倾向了呢?
答案是肯定的。简单来说,基于词典的情感分析的一般流程:
构建/下载情感词典
对文本进行分词
将分词结果匹配情感词典
根据评分和反转极致,通过合适的算法,计算出文本的情感得分。
比如,我们取一段酒店入住评价来举例子。
原文:前台楼层服务员不错,房间安静、整洁,唯一卫生间地漏设计不好,导致少量积水。
分词结果:前台 楼层 服务员 很 不错 房间 安静 整洁 唯一 卫生间 地漏 设计 不好 导致 少量 积水
匹配词典:
正向匹配:很,不错,安静,整洁
负向匹配:不好,积水
情感得分:4-2=2
来自 掘金 《浅谈如何做情感分析》
当然,这里只是用简单的评分加总举例,考虑到中文的博大精深,实际上的算法比这要复杂。但经过这样的批量自动化的筛选,至少可以得出一个大概的评价倾向范围,省去了不少人工。
我们继续了解一下第二种方法「基于机器学习的情感分析」
通过算法模型获取特征词,形成文本和词的矩阵,再利用机器学习/深度学习等方法进行分类。分类效果取决于训练文本的选择以及正确的情感标注。
来自 华天情 文本情感分析的学习笔记 知乎
一般流程是:
选一部分语料,标记出情感分类,正向标注为1,负向标注为0,分成训练数据和测试数据。
选取文本中的「特征词」,比如商品的描述词(简约、时尚)等等,将词转化成向量,形成词的矩阵。
使用分类器模型(LR、SVM、NB)对训练数据进行学习,得到模型后,用测试数据进行预测,选取效果最优的模型。
这个不仅仅是「基于机器学习的情感分析」的流程,基本上涉及「机器学习」的都离不开这几个步骤,机器学习需要一定的数学基础,涉及到很多公式的演算,这里就不做展开了,但如果想探究下机器学习的领域,「文本情感分析」倒是个不错的入门训练。
到这里,如何做情感分析,各位应该有个大致的概念了,也没有那么玄乎对吧?机器的世界就是这样,设定好了规则,它就按照规则有秩序地执行。
那么我们假设,在微信里,语音首先被转成了文字,然后通过「情感分析」得出文字的情感倾向,再根据情感倾向去判断添加何种表情。似乎是行得通的一条路。
但我又做了另外一个测试,情况似乎不是这样:
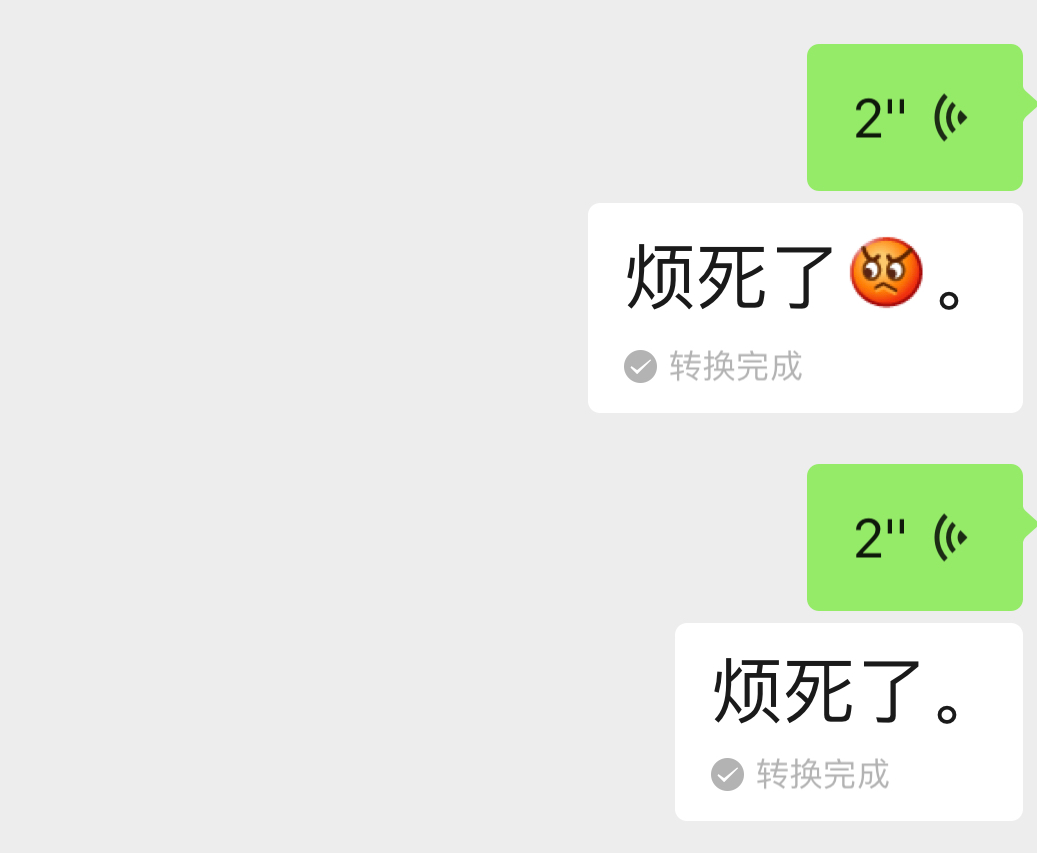
为什么,第二个「烦死了」没有表情呢?说下背景,在我说第二个「烦死了」的时候,我几乎是一个字一个字往外蹦的,相比第一个真的有那么一点点「烦死了」的情绪,第二个的语气和语调相对比较平和了。
这样的例子还有很多,比如,请脑补一下,撒娇式的「讨厌」和厌恶式的「讨厌」,能一样吗?对计算机来说,文本显示的都是「讨厌」,打分一样,它要如何分辨?
你一定想到了,对,就是「语调」,请再回放一下撒娇式的「讨厌」和厌恶式的「讨厌」,语调一样吗?
其实不止「语调」,包括「语速」「强度」「基频」都与人的情绪有关系。只要有这些可以量化的指标,那么对于计算机来说,就是有章可循,可以完成的自动化工作。感兴趣的可以搜索「语音情感识别」了解更多。
综上,我的猜想是微信用了文本+语音情感分析相结合的方法。如有知情的微信研发的小伙伴,欢迎交流~
功能二:语音直接转文字发送
用惯了讯飞输入法的朋友对这种功能一定很熟悉,说一段语音自动转成文字发送出去,省去了打字的麻烦,同时又不给对方带来困扰。
现在微信也有这功能啦,右边「转文字」的就是,直接发出去的就是已经识别好的文本。
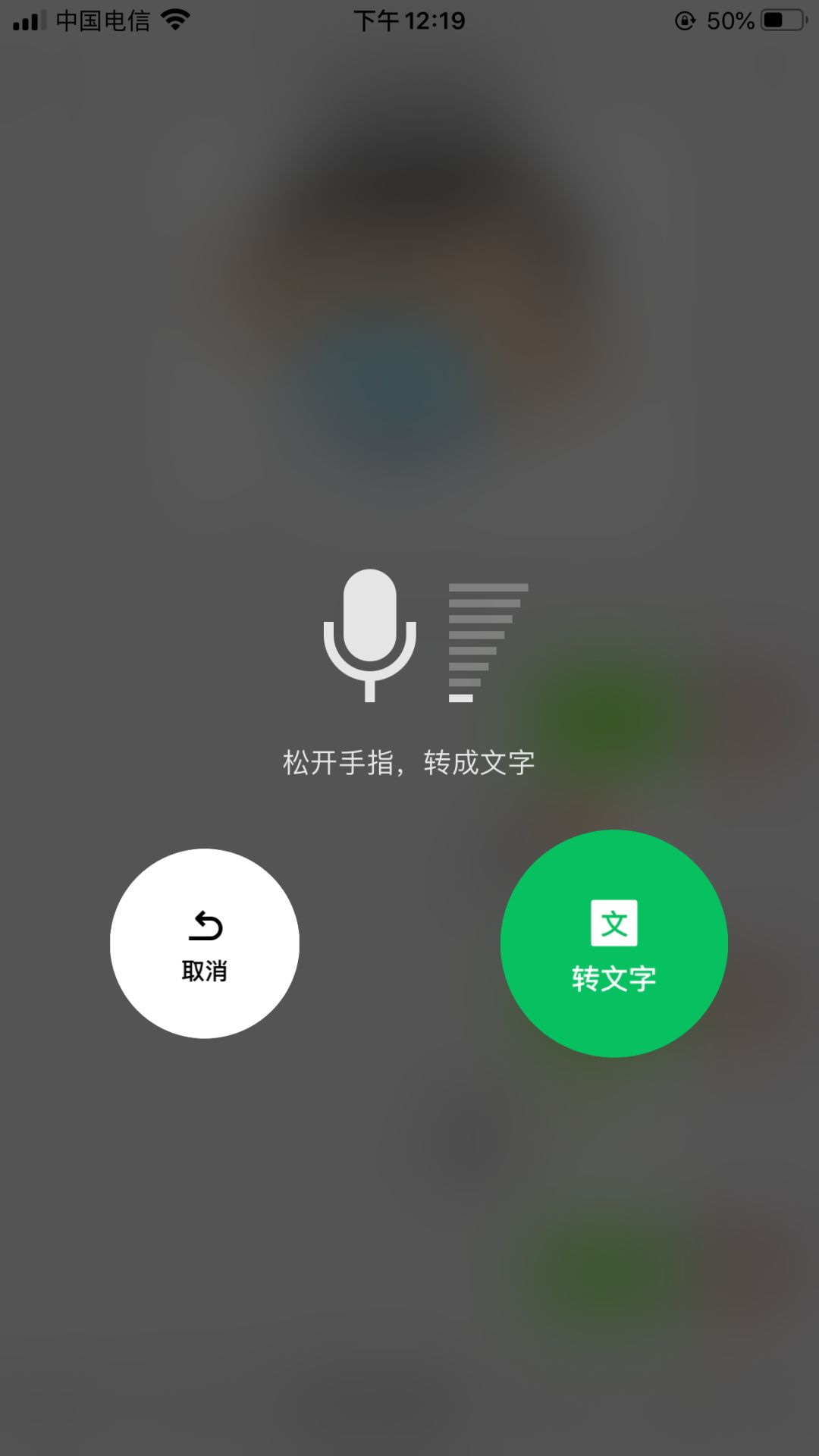
发现这个功能,还是因为家里小小小朋友突然开始给我发大段文字,字里行间我“嗅”出了「自动转换」的味道,一试才发现是微信语音里就有的功能。
微信语音这个功能对于整个微信的架构来说,可能是非常非常小的一部分,但产品团队在这个“小”功能上的细节打磨,让用户有了一种「小确幸」的体验。如今科技发达了,在未来,声音和视频一定会拥有更广阔的应用场景,拭目以待。
后记:
在意外发现了微信语音的这两个功能之后,想起在学校的时候做过一个「中文情感词分析」的课题项目,当中原理不是很复杂,加上在网上看到很多业外人士觉得「加表情」这个功能很神奇但又不知如何实现的,就想着来写一篇科普小文吧。
原本以为可以如往常写文一般只需1-2小时,结果,这篇文章,差不多花了我三天的时间,当中大多数时间都在查阅资料,有很多太深的内容就没有放上来,整理好了,发现要把这件事说明白也并不是一件容易的事。
所以说,研发评估工作量需要一定的 Buffer 是有道理的,有时候太过于自信,需时刻谨记我们随时都会碰到 Yak Saving,参见 冬日里的一次 Yak Saving
中文情感词汇本体库 via 大连理工大学信息检索研究室
https://figshare.com/articles/___/6881282/1 ↩
发送给作者