
题图来自于NextDay
工具:
Python
BeautifulSoup 库
email 库
我在 往前一小步 中提到过一个用 Python 写的抓取网页的小脚本,今天来分享下怎么实现的,继续抛砖引玉,如果你的专业不是计算机,想学习 Python,同时对网页爬虫有兴趣的话,可以从这里开始。
但是记住,爬虫,只是工具,切记善用工具,善良的善。
Mac 自带 Python 的运行环境,Windows 的话,下载一个安装下,也非常方便,此处就略过安装过程了。
写这个脚本的初衷是因为那段时间要关注某个考试的领证通知,又不想每次都打开那个网页,最简单的需要就是通过脚本去抓取网页内容,并发送邮件给我。
那么,第一步是要分析网页的源代码,网页右击查看源码,此处还是以我例子中的领证通知的网页为例。
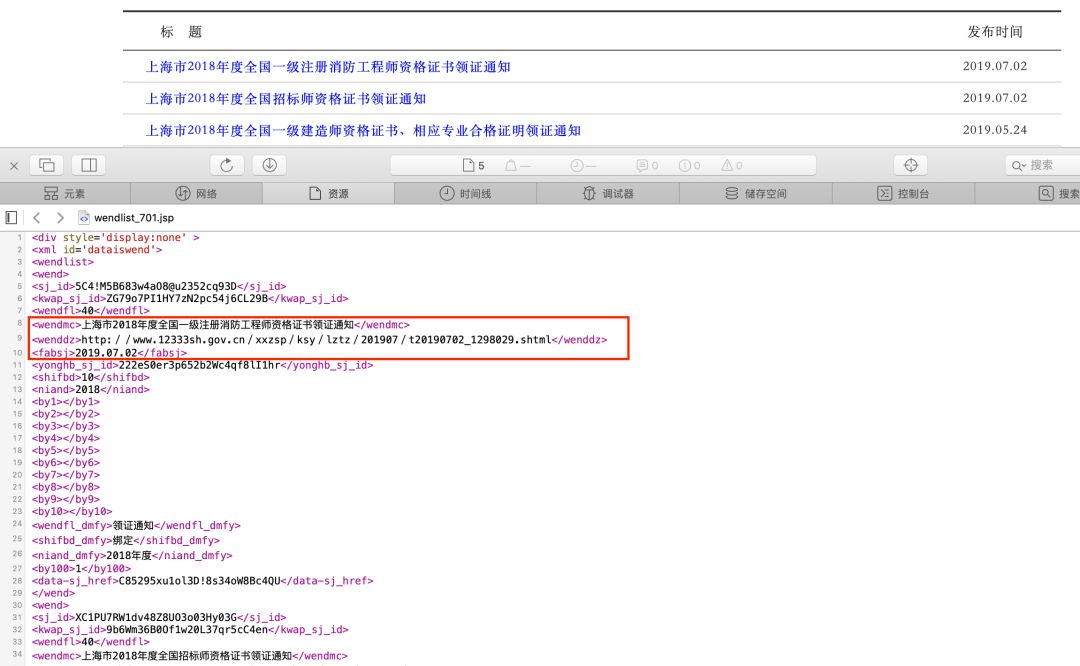
这个网页有点特殊,它的源文件是一个 格式化很好的 XML 文件,标签比 HTML 更清晰。所有通知都包裹在 wendlist 这个数组里面,然后每个 wend 就是每一行的通知,我所关注是红色框出的这三个元素:标题、链接、日期。在这一步,我们拿到了 wendmc、wenddz、fabsj 这三个标签。接下来就是交给 BeautifulSoup 处理了
首先,我们需要获取整个网页内容,通常是通过一个 http request 来实现,decode(‘gbk’) 不是必需的,需要根据网页的源码具体判断。然后将内容丢给 BeautifulSoup 解析,soup 可以理解成一个格式化好的 BeautifulSoup 对象。
html = requests.get('网址').content.decode('gbk')
soup = BeautifulSoup(html, 'html.parser')
那么,接下来就是从这个 soup 中取出前面我们提到的那三个标签了,首先我们要取出所有的 wend (每条通知就是一个 wend),并且顺藤摸瓜找到标题、链接、日期。
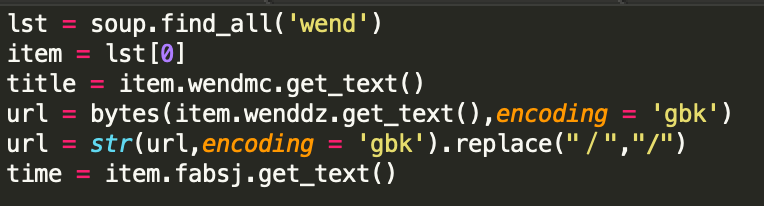
中间关于 url 的特殊处理,主要是有个中文的斜杠的原因,可以不用在意。这段代码只取了第一条通知(lst 0)作为例子,如果需要所有的,可以用循环去做处理。
网页抓取的部分就到这里,是不是看上去挺简单的,BeautifulSoup 很强大是真的,但也跟这个网页本身有关系,XML 格式本身就非常易读了,其实不需要用爬虫工具就可以处理了。但主要还是想给完全没有基础的人一个大体上的概念,怎么一步步来做。
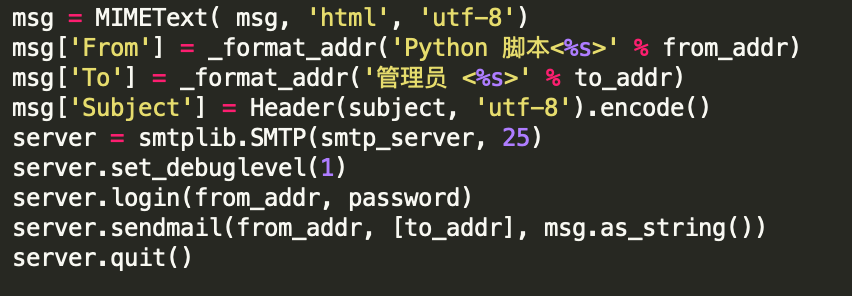
最后贴一下发邮件的代码,这个网上一搜很容易找到,没什么特别,可以将我们前面获取到的这些数据以邮件的形式发给我们。
有人说,程序员其实是世界上最懒的人,只要是能让机器做的,绝不会手工去处理,所以会为自己准备一堆堆的脚本或者小程序。未来,可能人人都会或者说都需要懂一点编程语言,除了人工智能的潮流势不可挡,也可以在一定程度上把自己从一些小繁琐中解救出来。
这是 HOW TO 系列的第三篇,前面两篇在文后可以看到。这个系列的初衷,我在 回归初心 中提到的,因为平时写的关于「WHY」或者心理活动方面的文章,「HOW TO」系列更偏向于实用。另外一点在于,我发现,有些本行业内认为小儿科或者不值得一提的工具或者方法,对于大多数行业外的人来说,还是比较陌生的,本着「抛砖引玉」的想法,想让大家可以通过这些「砖」打开思路,也可以了解到一些平常不太接触得到的一些东西。
最后,还是那句话,工具是不带好恶属性的,带好恶的是使用它的人,比如爬虫,其实是个挺有用的技术,可以解决很多手工化的繁琐工作,但如果不善用,也会带来不必要的麻烦。
善用工具,善良的善
旧文参考:
发送给作者